Maths | p-value | Statistical Significance
p-value
In null-hypothesis significance testing, the p-value is the probability of obtaining test results at least as extreme as the result actually observed, under the assumption that the null hypothesis is correct.
p值(p value)就是當虛無假設為真時所得到的樣本觀察結果或更極端結果出現的概率。如果p值很小,說明在虛無假設下極端觀測結果的發生概率很小。而如果出現了,根據小概率原理,就有理由拒絕虛無假設;p值越小,拒絕虛無假設的理由越充分。
常常看到有人說p-value <0.05,所以達到統計上的意義,模型合理,但你真的知道這是什麼意思嗎? p 值是什麼? p 值是由 Ronald Fisher 在 1920 年代發展出來的,已將近一百年。p 值檢定最開始,是檢定在一個 model 之下,實驗出來的 data 跟 model 到底吻合不吻合。這個被檢定的 model,我們把它叫做虛無假設(null hypothesis),一般情況下,這個被檢定的 model,是假設實驗並無系統性效應的,即效應是零,或是隨機狀態。在這個虛無假設之下,得到一個統計值,然後要算獲得這麼大(或這麼小)的統計值的機率有多少,這個或機率就是 p 值。我們得到 p 值以後,要作統計檢定。我們相約成俗地設定一個顯著水準,叫做 α,α 通常都是 0.05,有時候大家會嚴格一點用 0.01,比較不嚴格則用 0.10。如果我們的 α = 0.05,則若 p < 0.05,我們就可以拒絕虛無假設,並宣稱這個檢定在統計上是顯著的,否則檢定就不顯著,這是傳統的 p 值檢定方法。如果統計上顯著的話,我們就認為得到實驗結果的機會很小,所以就不接受虛無假設。


Statistical hypothesis test
A statistical hypothesis test is a method of statistical inference used to decide whether the data sufficiently supports a particular hypothesis. A statistical hypothesis test typically involves a calculation of a test statistic. Then a decision is made, either by comparing the test statistic to a critical value or equivalently by evaluating a p-value computed from the test statistic. Roughly 100 specialized statistical tests have been defined.
Student's t-test

Student's t-test is a statistical test used to test whether the difference between the response of two groups is statistically significant or not. It is any statistical hypothesis test in which the test statistic follows a Student's t-distribution under the null hypothesis. It is most commonly applied when the test statistic would follow a normal distribution if the value of a scaling term in the test statistic were known.

雖然 t 檢定相對於假設的差異較為穩固,t 檢定實際上假設:
資料為連續資料。
樣本資料必須從母體隨機採樣。
變異數具同質性 (各群組資料的變異性相似)。
資料趨近於常態分佈。
針對雙樣本 t 檢定 (Two sample t test),我們必須有獨立樣本。若樣本並非獨立,則使用配對t檢定 (Paired t test)可能會較為合適。
When the normality assumption does not hold, a non-parametric alternative to the t-test may have better statistical power.
- Nonparametric statistics is a type of statistical analysis that makes minimal assumptions about the underlying distribution of the data being studied. Nonparametric tests are often used when the assumptions of parametric tests are evidently violated.
- The first meaning of nonparametric involves techniques that do not rely on data belonging to any particular parametric family of probability distributions.
- 非參數統計學(英語:nonparametric statistics),或稱無參數統計學、非參數統計分析,是統計學的一個分支,適用於總體分佈情況未明、小樣本、總體分佈不為正態也不易轉換為正態。
- 參數統計(Parametric statistics)是統計學的一個分支,它假設樣本數據來自總體,而總體可以透過具有固定參數集的概率分佈 (e.g.正態分佈族) 進行充分建模。
Wilcoxon signed-rank test
The Wilcoxon signed-rank test is a non-parametric rank test for statistical hypothesis testing used either to test the location of a population based on a sample of data, or to compare the locations of two populations using two matched samples.
- 单样本Wilcoxon符号秩检验(One Sample Wilcoxon Signed Rank Test)——理论介绍
- 单样本Wilcoxon符号秩检验(One Sample Wilcoxon Signed Rank Test)——Python软件实现
- 配对样本Wilcoxon符号秩检验(Paired Samples Wilcoxon Signed Rank Test)——理论介绍
- 配对样本Wilcoxon符号秩检验(Paired Samples Wilcoxon Signed Rank Test)——Python软件实现
- 兩組成對資料Wilcoxon signed-rank檢定 (Wilcoxon signed-rank test for paired samples,non-parametric)
Applications
- Significance
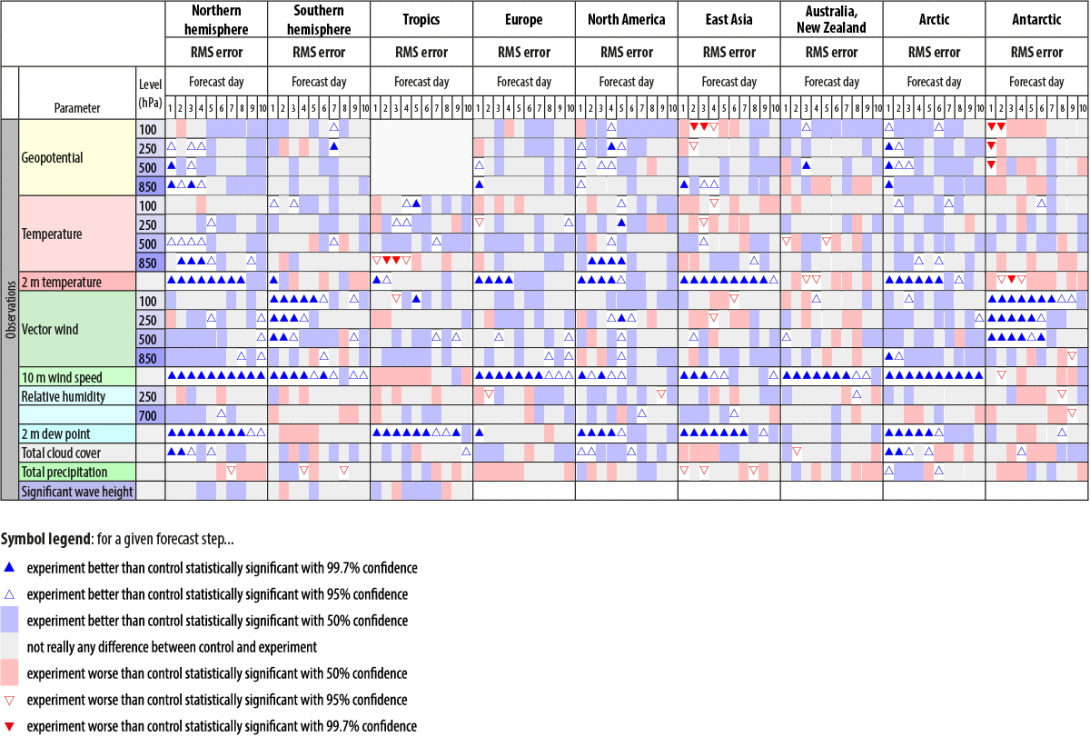
of changes in medium-range forecast scores | ECMWF | 2015
- By making an independent realisation of the null distribution used in the hypothesis testing, using 1,885 paired forecasts (about 2.5 years of testing), it is possible to construct an alternative significance test that makes no statistical assumptions about the data.
- A main issue is that chaotic error growth leads to large differences in skill between any two forecasts.
- This study focuses on medium-range (day 3 to day 10 here) extratropical forecast scores of which the quintessential example is the root-mean-square (RMS) error in 500 hPa geopotential height.
- The RMS error as a function of lead-time (Fig. 2) illustrates the rapid baroclinic error growth in midlatitudes.
- As mentioned, the usual basis of significance testing is to create a population of paired differences in scores between an experiment and a control (e.g. Wilks, 2006).
- ** It can also be used to create an entirely non-parametric significance test, i.e. one that makes no assumptions on the distributions of forecast scores.
- The solution (Fisher, 1998; Wilks, 2006) is to look at the paired differences,
- The time-autocorrelation between paired differences at day-5 is 0.15 for base times separated by 12 h and 0.07 for separations of 24 h. Autocorrelation is essentially zero for any longer period.
- However, for now we will assume that taking paired differences has created a statistical population that has sufficiently little autocorrelation that a normal t-test can be used to test for statistical significance.
- Improved
two-metre temperature forecasts in the 2024 upgrade | ECMWF | 2024
- The grey rectangles show 95% confidence intervals
References
- T-Tests and P-Values
- (推薦)| t 檢定與中央極限定理:你真的懂常態分佈嗎?
- 使用
Python 进行 T检验
- 单样本T检验(ttest_1samp)
- 两独立样本T检验(ttest_ind)
- 配对样本T检验(ttest_rel)
- 【學習筆記】獨立樣本t檢定-理論+Python實作
- 看電影學統計: p值的陷阱
- 統計學:大家都喜歡問的系列-p值是什麼
- t 檢定
- Wilks, D. S. (2006, 2011). Statistical methods in the atmospheric sciences. Academic press.