NWP | Anomaly Correlation Coefficient (ACC)
Anomaly Correlation Coefficient (ACC)
- https://confluence.ecmwf.int/display/FUG/Section+6.2.2+Anomaly+Correlation+Coefficient
- ECMWF_ACC_definition
The Anomaly Correlation Coefficient (ACC) is one of the most widely used measures in the verification of spatial fields. It is the spatial correlation between a forecast anomaly relative to climatology, and a verifying analysis anomaly relative to climatology. ACC is a measure of how well the forecast anomalies have represented the observed anomalies. It shows how well the predicted values from a forecast model "fit" with the real-life data. ACC for a series of forecast lead-times is a measure of how well trends in the predicted anomalies follow trends in actual anomalies.
The correlating forecasts directly with observations or analysesmay give misleadingly high values because of the seasonalvariations. It is therefore established practice to subtractthe climate average from both the forecast and the verification and toverify the forecast and observed anomalies according to the anomalycorrelation coefficient (ACC).
ACC values lie between +1 and -1. Where ACC values:
- approach +1 there is good agreement and the forecast anomaly has had value.
- lie around 0 there is poor agreement and the forecast has had no value.
- approach –1 the agreement is in anti-phase and the forecast has been very misleading.
Where the ACC value falls below 0.6 it is considered that the positioning of synoptic scale features ceases to have value for forecasting purposes.

What the ACC Measures
The fundamental purpose of the ACC is to determine how well the forecast model captures the large-scale pattern and location of weather features that deviate from the long-term normal (the climatology).
- Anomaly Calculation: An anomaly is the deviation of
a variable (e.g., \(500 \text{ hPa}\)
geopotential height) from its long-term average for that
specific time and location (the
climatology).
- Forecast Anomaly (\(F'\)): \(\text{Forecast} - \text{Climatology}\)
- Observed Anomaly (\(A'\)): \(\text{Observation} - \text{Climatology}\)
- Correlation: The ACC is the Pearson correlation coefficient applied to the forecast anomalies (\(F'\)) and the observed anomalies (\(A'\)) across all grid points in the verification domain (e.g., the Northern Hemisphere).
The ACC is a measure of the pattern accuracy, not the magnitude of the errors.
The Formula
The ACC is mathematically defined as the spatial correlation between the forecast anomaly and the analysis (observed) anomaly:
\[ \text{ACC}_\text{uncentered} = \frac{\sum_i w_i F'_i A'_i} {\sqrt{\sum_i w_i (F'_i)^2}\,\sqrt{\sum_i w_i (A'_i)^2}} \]
or
\[\text{ACC}_\text{centered} = \frac{\sum_{i=1}^{N} w_i (F'_i - \overline{F'}) (A'_i - \overline{A'})}{\sqrt{\sum_{i=1}^{N} w_i (F'_i - \overline{F'})^2} \sqrt{\sum_{i=1}^{N} w_i (A'_i - \overline{A'})^2}}\]
Where:
- \(N\) is the total number of grid points in the domain.
- \(F'_i\) is the forecast anomaly at grid point \(i\).
- \(A'_i\) is the observed anomaly at grid point \(i\).
- \(\overline{F'}\) and \(\overline{A'}\) are the spatial mean of the forecast and observed anomalies, respectively (often calculated using weighting).
- \(w_i\) is the area
weighting coefficient for grid point \(i\) (used because grid cells closer to the
poles cover a smaller area).
- To counteract the shrinking area of grid cells towards the poles,
the most common and standard way to calculate the area weighting
coefficient is using the cosine of the latitude (\(\phi_i\)) for each grid point \(i\):
- \[\mathbf{w_i \propto
\cos(\phi_i)}\]
- At the Equator (\(\phi = 0^{\circ}\)): \(\cos(0^{\circ}) = 1\). The weighting is maximum, as these grid cells cover the largest area.
- Near the Poles (\(\phi \approx 90^{\circ}\)): \(\cos(90^{\circ}) \approx 0\). The weighting is near zero, effectively down-weighting the small grid cells to ensure they don't overly influence the final result.
- By multiplying the forecast and observed anomalies by \(\cos(\phi_i)\) before summing them in the numerator and denominator of the ACC formula, the calculation is essentially performed over an equal-area basis.
- In practice, the ACC formula uses the weighted sum of anomalies and their squares, ensuring the final correlation value accurately reflects the skill of the forecast model across the entire geographical domain.
- \[\mathbf{w_i \propto
\cos(\phi_i)}\]
- To counteract the shrinking area of grid cells towards the poles,
the most common and standard way to calculate the area weighting
coefficient is using the cosine of the latitude (\(\phi_i\)) for each grid point \(i\):
The ACC ranges from -1 to +1, similar to the standard correlation coefficient:
| ACC Value | Interpretation | Skill Implication |
|---|---|---|
| +1.0 | Perfect correlation. The forecast and observed anomaly patterns are identical. | Perfect Skill |
| +0.6 | Typically considered the threshold where the forecast retains useful synoptic skill (good enough for general weather prediction). | Useful Skill |
| 0.0 | No correlation. The forecast pattern is no better than a random pattern. | No Skill |
| -1.0 | Perfect negative correlation. The forecast pattern is completely opposite of the observed pattern. | Very Misleading Forecast |
Key Applications
- Medium-Range Forecasts: The ACC of the \(500 \text{ hPa}\) geopotential height (a proxy for the jet stream and large weather systems) is often the headline score used by major weather centers like ECMWF to track skill improvement over time.
- Forecast Horizon: ACC is commonly plotted against forecast lead-time (days) to determine the effective limit of predictability. For instance, if the ACC drops to \(0.6\) at Day 10, the forecast is considered useful up to 10 days.
ACC vs. Other Metrics
The ACC is excellent for pattern but has limitations:
| Metric | Focus | Sensitivity |
|---|---|---|
| ACC | Pattern and Phase (Are the highs and lows in the right place?) | Not sensitive to bias (the difference in the mean magnitude). A forecast that is too cold everywhere but has the correct pattern will still score high. |
| Root Mean Square Error (RMSE) | Magnitude of error (How far off are the values in standard units?) | Sensitive to both pattern error and overall forecast bias. |
Uncentered vs. centered
- Verification
Statistics for Continuous Forecasts | dtcenter
- Anomaly Correlation
- There are two widely used versions of anomaly correlation.
- The first is the centered anomaly correlation, which includes the mean error relative to the climatology. This version is calculated using
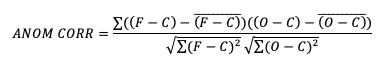
- If it is not desirable to include the errors, the uncentered anomaly correlation is the better choice:
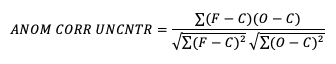
Anomaly correlation coefficient (ACC) can be defined in two slightly different ways, often called centered and uncentered; the distinction is about whether you remove the sample mean of the anomalies themselves before computing the correlation.
Uncentered anomaly correlation
The Uncentered ACC is a less common variation that measures the correspondence between the two anomaly fields without removing their spatial means.
This is what operational NWP centers almost always mean by “ACC”:
- Define anomalies relative to a climatology \(C\): \[ F'_i = F_i - C_i,\quad A'_i = A_i - C_i \]
- Compute the correlation directly from these anomalies, without removing any additional mean: \[ \text{ACC}_\text{uncentered} = \frac{\sum_i w_i F'_i A'_i} {\sqrt{\sum_i w_i (F'_i)^2}\,\sqrt{\sum_i w_i (A'_i)^2}} \]
Here the only centering is the subtraction of climatology; there is no subtraction of the domain/sample mean of \(F'\) or \(A'\).
This version keeps information about systematic errorsrelative to climatology (mean forecast anomaly vs. meanobserved anomaly over the domain).
Key Features:
- No Removal of Spatial Mean: The spatial averages (\(\overline{F'}\) and \(\overline{A'}\)) are not subtracted.
- Sensitive to Bias: The \(\text{ACC}_{\text{uncentered}}\) score is penalized if the overall spatial mean of the forecast anomaly differs significantly from the observed spatial mean anomaly. Therefore, it is sensitive to the overall bias of the forecast's anomaly field.
- Focus: It evaluates the pattern match and the similarity in the average magnitude of the anomalies across the domain.
Centered anomaly correlation
The Centered ACC is the standard and most commonly used form in meteorological and climate forecast verification. It is calculated by first removing the spatial mean from both the forecast anomaly field (\(F'\)) and the observed anomaly field (\(A'\)).
The centered ACC is the Pearson product-moment correlation coefficient of the two anomaly fields:
\[\text{ACC}_{\text{centered}} = \frac{\sum w_i (F'_i - \overline{F'}) (A'_i - \overline{A'})}{\sqrt{\sum w_i (F'_i - \overline{F'})^2} \sqrt{\sum w_i (A'_i - \overline{A'})^2}}\]
Where \(F'_i\) is the forecast anomaly, \(A'_i\) is the observed anomaly, \(\overline{F'}\) and \(\overline{A'}\) are the spatial mean anomalies, and \(w_i\) is the area weighting coefficient.
Key Features:
- Removal of Spatial Mean: The spatial average of the anomalies (\(\overline{F'}\) and \(\overline{A'}\)) is subtracted from the respective fields before calculating the correlation.
- Insensitive to Bias: The \(\text{ACC}_{\text{centered}}\) measures the similarity of the two patterns' shapes, regardless of the magnitude difference (bias) between the overall spatial mean of the forecast anomaly and the observed anomaly.
- Focus: It only evaluates the pattern match and phase agreement (i.e., whether the predicted high-pressure systems and low-pressure systems are in the correct geographical locations).
Summary of the Difference
| Feature | Centered ACC (\(\text{ACC}_{\text{centered}}\)) | Uncentered ACC (\(\text{ACC}_{\text{uncentered}}\)) |
|---|---|---|
| Calculation | Removes the spatial mean (\(\overline{F'}\) and \(\overline{A'}\)) from the anomaly fields. | Does NOT remove the spatial mean from the anomaly fields. |
| Sensitivity | Insensitive to the forecast's overall bias. | Sensitive to the forecast's overall bias. |
For example, if a model correctly predicts a cold air outbreak over North America but predicts that the air is \(2^\circ \text{C}\) colder on average than what was observed across the domain, the Centered ACC would still be very high (due to the correct pattern), while the Uncentered ACC would be noticeably lower (penalized for the \(2^\circ \text{C}\) cold bias).
ERA5 for Climatological term
1. Defining Climatology (Climate Normal)
- A Climatology (or Climate Normal) is the long-term average of a meteorological variable, typically calculated over a 30-year period (e.g., 1981–2010 or 1991–2020) as defined by the World Meteorological Organization (WMO).
- ERA5's Role: Since ERA5 provides consistent, continuous, gridded data for a long period (1940–present), researchers can use it to calculate climatologies for virtually any location on Earth for which ERA5 has data. For example, the mean temperature for every January 1st over the 1991–2020 period is derived directly from ERA5 data.
2. Calculating Anomalies
- An Anomaly is the deviation of a specific weather event or period from the climatological normal.
- ERA5's Role: By subtracting the long-term
climatology (calculated from ERA5) from the
hourly or daily ERA5 value for a specific day, you get the anomaly. This is essential for studying extreme events (e.g., a heatwave's temperature anomaly) and for climate monitoring (e.g., global temperature anomalies).
3. Consistency and Homogeneity
- Climatological studies rely on homogeneity—the data must be comparable across the entire time series.
- ERA5's Role: It achieves this by using a single, modern, fixed numerical weather prediction model and data assimilation system to integrate all observations (satellite, ground station, etc.) from the past 80+ years. This process "fills the gaps" where observations were sparse and ensures that changes in the climate signal are due to the atmosphere, not due to changes in the measurement instruments or models over time.
In summary, when a climate scientist mentions a climatological mean, anomaly, or reanalysis in the context of global data, they are most often referring to calculations derived from a product like ERA5.
ERA5 download
- ERA5 hourly data on single levels from 1940 to present
- ERA5 hourly data on pressure levels from 1940 to present
- ERA5 monthly averaged data on single levels from 1940 to present
- ERA5 monthly averaged data on pressure levels from 1940 to present
Downloading ERA5 Single-Layer Data
This guide provides instructions for downloading single-layer atmospheric variables from the ERA5 reanalysis dataset using the ECMWF CDS API (Climate Data Store Application Programming Interface).
Important Data Caveats
1. Daily Updates and Preliminary Data (ERA5T)
- The ERA5 dataset is updated daily with a latency of approximately 5 days.
- The most recent data is initially released as ERA5T (T for "Timely"). This is a preliminary release.
- In the event that serious flaws are detected in the ERA5T data, the final re-release (which occurs 2 to 3 months later) may contain corrections and differ from the ERA5T version. Users are notified if such differences occur.
2. File Format and Size
- All data downloaded via the CDS API is typically provided in GRIB format.
- For bulk data processing or conversion to NetCDF, consider using
tools like
grib_to_netcdf(with the-k 4flag for large files) or Python libraries likexarrayandcfgrib.
Standard Single-Layer Download
Requests Mean Sea Level Pressure (msl), 2m Temperature (t2m), and 10m wind components (u10, v10) for a single day.
Then,
1 | |
Downloading ERA5T (Real-Time Data)
If you need the very latest, most current data (the ERA5T version, which is generally available up to 5 days ago)
Pressure Level Data Download
Use a common subset for efficiency:
1 | |
Then,
1 | |
Build the ERA5 climatology field
The goal is a mean state (climatology) \(C(t_{\text{cal}}, x)\) for each calendar time and grid point, using only ERA5.
- Decide which ERA5 product to use (hourly, daily or monthly) and which variable, e.g. 500 hPa geopotential height, 850 hPa temperature, 2 m temperature, etc.
- Select a long reference period, typically 30 years such as 1981–2010 or 1991–2020, so the climatology is stable.
- Extract ERA5 for the full reference period for your variable and pressure level.
- Decide temporal resolution for climatology:
Daily: all 1 Jan values across years, all 2 Jan, … (possibly smooth with a running window).- Monthly: all Januaries, all Februaries, etc.
- For each calendar day (or month) and grid point,
average across all years:
\[ C(d, x) = \frac{1}{N_{\text{years}}} \sum_{y=1}^{N_{\text{years}}} \text{ERA5}(y, d, x) \]
where \(d\) is the day-of-year (or month) index and \(x\) is the grid point.
This yields a 3‑D array for daily climatology: \((\text{day}, \text{lat}, \text{lon})\), or \((\text{month}, \text{lat}, \text{lon})\) for monthly.
Implementation notes
- For daily climatology, you may use a running window \((± 7 days)\) for smoother anomalies. link
- For climate normals (monthly or annual), use monthly groupings.
- For soil moisture or other surface variables, ERA5-Land provides higher spatial resolution.
Align model forecasts and ERA5 analyses with climatology
- For each forecast valid time \(t\), determine its calendar day (or month) \(d\).
- Interpolate the climatology \(C(d, x)\) in time if needed, e.g. from monthly mean \(C(\text{month}, x)\) to daily valid times.
- Make sure the climatology is defined on the same grid as the forecast and analysis fields; if not, interpolate ERA5 or the model fields to a common grid first.
Compute anomalies
For each forecast case and grid point \(x\):
- Forecast anomaly:
\[ F'(t, x) = F(t, x) - C(d(t), x) \]
- Analysis (verification) anomaly using ERA5:
\[ A'(t, x) = A(t, x) - C(d(t), x) \]
Using the same climatology for both is essential; do not use separate climatologies for forecast and verification when computing ACC.
Average anomalies over time / cases / domain if desired
Often ACC is computed for a sample of forecasts at the same lead time over many initial dates.
- Collect all \(F'\) and \(A'\) at a given lead time over the selected period.
- Compute spatial means needed for correlation using that full set, e.g. subtract the spatial mean anomaly before computing covariance if using the covariance form of ACC. [be or not be]
This yields one ACC value per lead time (and region and variable).
ERA5: check: convert Gregorian time to datetime
- To check the validation of time of ERA5
- To convert the time value from an ECMWF/ERA5 NetCDF file using Python's datetime and timedelta modules.
1 | |
grib files: Duplicate
1 | |
- check duplicated terms
1 | |
- python script
1 | |
- check dimensions of .nc filenames
1 | |
proleptic_gregorian vs gregorian
Your original time data (1292630400, 1292716800, ...)
are large integers, suggesting units of seconds since a
distant epoch (likely 1970-01-01).
Your target time data (1060272, 1060296, ...) are much
smaller integers, suggesting units of hours (or days)
since a more recent epoch.
To make this transformation, you need to use the
cdo settime or
cdo setreftime functions to redefine the
time axis based on a new reference date and time unit.
- cdo setreftime change the format of time units
- Change the format of time:units
- New time format in ERA5 netcdf files
Method: Using CDO to Change Time Units and Reference
The CDO command needed is setreftime. This operator
allows you to set a new time unit and reference date for your time
axis.
1. Determine the Current and Target Time Axis
You first need to inspect both files to know their current time settings.
Original File (
input.nc):1
2# Check the attributes of the time variable
ncdump -v time input.nc- Original Units (Example):
seconds since 1970-01-01 00:00:00 - Original Calendar:
proleptic_gregorian
- Original Units (Example):
Target File (
target.ncor desired state):1
2# Check the attributes of the time variable on a file that has the desired format
ncdump -v time target.nc- Target Units (Example):
hours since 1900-01-01 00:00:00 - Target Calendar:
gregorian
- Target Units (Example):
2. Run the CDO
setreftime Command
Once you know the target units and reference date, you can apply them to your input file.
For the example above, where you want to change from
seconds since 1970-01-01 to
hours since 1900-01-01 and change the calendar:
1 | |
| Operator/Argument | Value | Description |
|---|---|---|
setreftime |
The CDO operator to redefine the time reference. | |
,1900-01-01 |
The new reference date (the "since" date). | |
,00:00:00 |
The new reference time. | |
,hours |
The new time unit (e.g.,
hours, days, seconds). |
|
input.nc |
Your original NetCDF file. | |
output.nc |
The new NetCDF file with the recalculated time axis. |
CDO automatically handles the calendar conversion and numerical
recalculation during this process. The setreftime operation
will:
- Read the old time values, old units, and old reference date.
- Calculate the absolute wall-clock time for each step.
- Calculate the difference between the absolute time and the
new reference date (
1900-01-01). - Express that difference in the new units
(
hours). - Set the
calendarattribute to a standard calendar (likegregorianorstandard).
3. Verification
After running the command, check the new file's time variable to ensure the new values match your expected smaller integers:
1 | |
This should show the smaller integers and the new time attributes
(units and calendar).
Calculate ERA5 climatology
1 | |
Result is,
1 | |
(Optional) Add
level(level)
1 | |
(Optional) Reordered the
level dimension
1 | |
(Optional) how to average two nc files with weighting?
Method: Weighted
Average using CDO (mul and add)
If you want to perform a more complex operation or if you have
weighting factors stored in a separate mask file, you can use the
sequential operators mul and add.
Scenario: Weighting by a Constant Value
If you want the exact same result as Method 1 but prefer using sequential operators:
1 | |
mulc,W: Multiplies the entire file's data by the constant \(W\).
Error: Warning (cdfCheckVars): 4 dimensional variables without time dimension are not supported, skipped variable z
- Warning (cdfCheckVars): 4 dimensional variables without time dimension are not supported, skipped variable z
That warning message from CDO (Climate Data
Operators), specifically the cdfCheckVars
function, indicates that your NetCDF file contains a four-dimensional
(4D) variable named z that CDO
cannot interpret correctly because it doesn't recognize the
expected time dimension.
CDO and many climate analysis tools are designed to work with structured data where the dimensions are typically:
- Time (the first dimension)
- Level (e.g., pressure, height)
- Latitude
- Longitude
When CDO encounters a 4D variable that doesn't follow this convention
(i.e., the first dimension is not marked as time), it skips
the variable, leading to the warning.
How to Resolve This Warning
You have two main options:
Rename the
Dimension to time (Recommended Fix)
If the first dimension of the variable z is
actually a time dimension, you need to use NCO (NetCDF
Operators) to rename it so CDO can recognize it.
Inspect the File: Use
ncdump -h your_file.ncto see the dimensions. Find the 4D variablezand look at its dimensions. Let's assume the first dimension is namedt_dim.- Original:
z(t_dim, level, lat, lon)
- Original:
Rename the Dimension: Use NCO's
ncrenamecommand to change the name of the first dimension totime.1
ncrename -d t_dim,time input.nc output.nc-d: Renames a dimension.t_dim,time: Changes the dimension namedt_dimtotime.
Check Time Variables: You might also need to rename the coordinate variable associated with that dimension (if it exists) and ensure its
unitsattribute is set correctly (e.g.,hours since 2000-01-01).
Example
1 | |
Error
1 | |
1 | |
But, if
An error occurred during renaming: Cannot rename time to dayofyear because dayofyear already exists. Try using swap_dims instead.
It means you have two distinct entities in your xarray Dataset with the name dayofyear:
- A data variable (or possibly a coordinate variable) named dayofyear already exists.
- You are trying to rename the dimension/coordinate variable currently called time to dayofyear.
1 | |
(Optional) int to float
int to floatorfloat to int
1 | |
(Optional) Remove var "time" and dim "time"
- how to remove a variable "time" first and then remove the dimension "time" from nc file?
1 | |
References
- Déqué, M. I. C. H. E. L., & Royer, J. F. (1992). The skill of extended-range extratropical winter dynamical forecasts. Journal of climate, 5(11), 1346-1356.
- Model Evaluation Tools | UCAR
- outline2013_Appendix_A.pdf | JMA
- Tutorial: Accessing ERA5-Land reanalyses and calculating a climate normal with Python
- The Ensemble Forecast System of the Central Weather Bureau (1995, gov.tw)